Architecting Enterprise AI: The Lattice Platform (Part 3)

Disclaimer: This series is a personal, educational reference architecture. All diagrams, opinions, and frameworks are my own and are not affiliated with, sponsored by, or representative of my employer. I’m publishing it on my own time and without using any confidential information.
© 2026 Sean Miller. All rights reserved.
From Gateway to Engine
The AI Gateway is the front door. It authenticates, validates, routes, and normalizes. But it doesn’t execute anything intelligent. Once the gateway accepts a request and selects a workflow, it hands off to the Orchestration Engine: the runtime that turns intent into action.
If the AI Gateway is the front door, the Orchestration Engine is the factory floor. It runs versioned, approved graphs of tool calls, model calls, and human checkpoints with persisted state and step-level auditability. Every run is governed, replayable, and testable.
Why Orchestration Matters
Ad hoc “agents” typically fail in three ways.
First, they lack determinism around non-determinism. When your agent decides what to do next, there’s no contract for what steps are allowed, what state must be preserved, or how to recover when something fails. The LLM just does whatever it does.
Second, they lack governed tool use. Tools get invoked without allowlists, schemas, retries, so there are zero idempotency guarantees.
One hallucinated function call can corrupt production data or trigger an irreversible action.
Third, they lack replayability. When something goes wrong, there’s no step-level log showing what context was consumed, what decisions were made, or what outputs were produced. Debugging becomes guesswork. Auditing becomes impossible.
The Orchestration Engine solves all three problems by treating agentic behavior as workflow execution with explicit contracts at every boundary.
Orchestration Engine Responsibilities
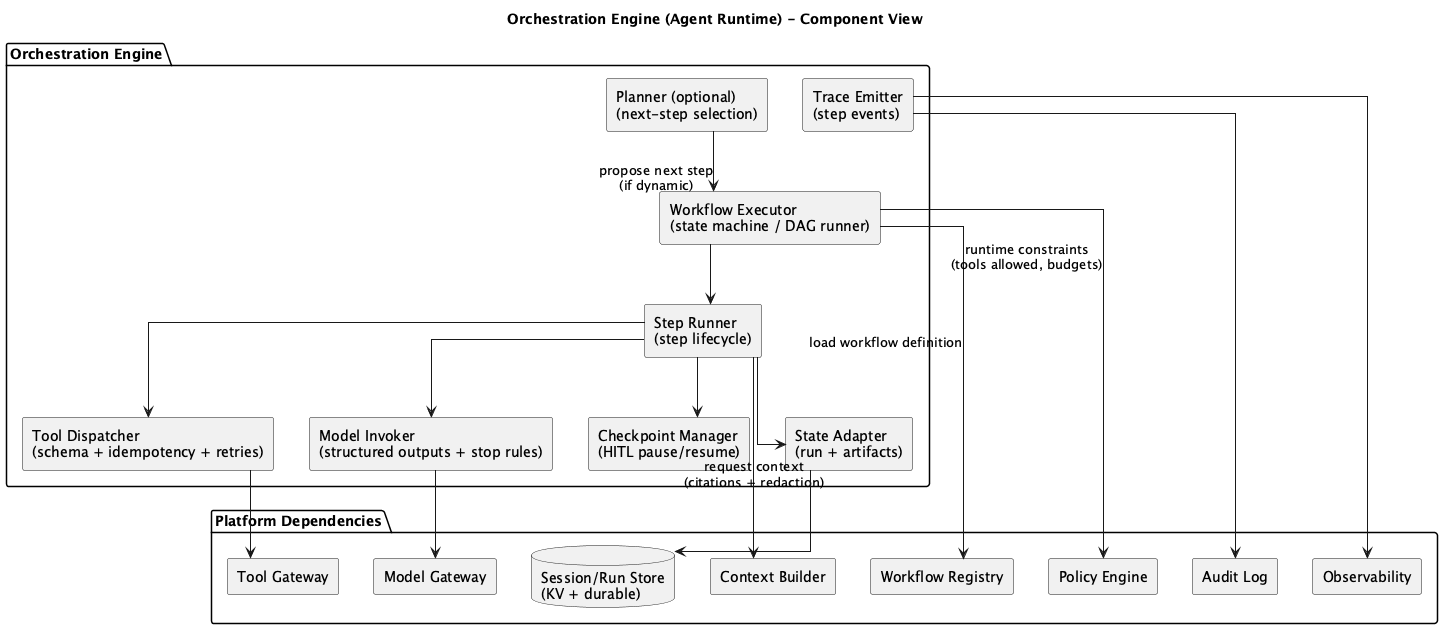 Figure 1: Orchestration Engine Component Diagram
Figure 1: Orchestration Engine Component Diagram
The Orchestration Engine owns workflow execution: running graphs and steps, handling branching, timeouts, retries, and fallbacks. It maintains run state and step state, including references to intermediate artifacts. The engine enforces tool invocation discipline through schema validation, idempotency keys, rate limits, and safe retries. It applies model invocation discipline via routing hints, structured outputs, and stop conditions. It manages human-in-the-loop checkpoints by pausing execution, requesting approval, and resuming when granted. And it ensures traceability through step-level logs, causal chains, and replay support.
The engine also enforces runtime policy: tool allowlists, data scope constraints, and context budgets. Every decision passes through policy before execution.
Orchestration Engine Explicit Non-Responsibilities
The Orchestration Engine should not:
- Access databases directly (that’s the Tool Gateway)
- Build indexes (that’s the Ingestion Plane)
- Make identity decisions (that’s the AI Gateway and policy engine)
- Contain domain-specific business logic scattered in the runtime (keep logic in workflows and tools)
This separation keeps the engine focused on what it does well: reliable, auditable execution of governed workflows.
Inside the Engine
When people say “agentic,” you can map it to these internal components:
| Component | Responsibility |
|---|---|
| Workflow Executor | Runs the graph or state machine |
| Planner | Decides next steps when the workflow allows flexibility (optional) |
| Tool Dispatcher | Executes tool calls through the Tool Gateway with constraints |
| Model Invoker | Calls the Model Gateway and enforces output schemas |
| State Store Adapter | Persists run state to the Session Store or durable store |
| Checkpoint Manager | Handles HITL pauses and resumes |
| Trace Emitter | Emits structured run and step events to audit and telemetry |
Each component has a clear boundary. The Workflow Executor coordinates. The Planner advises. The dispatchers and invokers execute under strict contracts. The adapters persist. The emitters observe.
Workflow Definition
A workflow is a versioned, approved state machine with explicit schemas and policies. Each workflow defines:
- Step types: tool call, model call, rule check, human checkpoint
- Explicit schemas: input and output contracts for each step
- Explicit policies: data scope, allowed tools, maximum budget
- Explicit success criteria: what constitutes completion and how to evaluate it
This is the core architectural move: agents become workflows with guardrails. The workflow definition is code-reviewed, version-controlled, and deployed through your standard CI/CD pipeline. There are no ad hoc prompt chains that drift between deploys.
# Example workflow definition (illustrative)
workflow:
id: case-risk-summary
version: "1.2.0"
owner: processing-team
steps:
- id: gather-context
type: tool
tool: document-retriever
input_schema: { caseId: string }
output_schema: { documents: Document[] }
- id: analyze-risk
type: model
model_class: high-accuracy
input_schema: { documents: Document[], prompt: string }
output_schema: { riskFactors: RiskFactor[], summary: string }
constraints:
max_tokens: 4000
required_citations: true
- id: human-review
type: checkpoint
trigger: { riskLevel: "high" }
timeout_hours: 24
escalation: processing-lead
policies:
allowed_tools: [document-retriever, policy-lookup]
data_scope: [case-documents, policy-rules]
max_cost_usd: 0.50
max_duration_minutes: 5The workflow definition is declarative. The Orchestration Engine interprets it. This separation means you can update policy constraints without touching the execution logic.
The Planner
Not all workflows are linear. Sometimes the next step depends on context: the user asks something unexpected, new documents arrive mid-case, a tool call fails and needs a fallback, or the system must choose between summarizing and drilling down based on signal.
The Planner is an optional decision-maker that chooses which step to run next when the workflow permits flexibility. The safest design treats it as a recommendation engine constrained by policy.
Planner Principle
The planner suggests; the executor decides. Planning is constrained to selecting among enumerated, approved next steps, and the executor validates every decision against policy and budgets before execution.
Given:
- The current workflow definition (graph)
- Current run state (what’s already happened)
- Constraints (allowed tools, budgets, HITL rules)
- Latest user input or signals
The planner returns a plan decision:
- Next step ID(s)
- Parameters for those steps
- Justification trace (optional but valuable for audit and debug)
The Workflow Executor then validates that decision against guardrails before proceeding.
Planner Types
Different scenarios call for different planner implementations:
Deterministic Planner (No AI): Best for strict compliance flows. The “plan” is if/else logic encoded in rules. No model involved. Maximum predictability.
Hybrid Planner (Rules First, Model for Ambiguity): Rules handle 80-90% of routing. The model is used for classification, intent extraction, or tie-breaking. This balances predictability with flexibility.
LLM Planner (Model Chooses the Path): The model selects among enumerated next steps. It must output strict JSON, cannot call tools directly, and can be forced to provide confidence and reasoning. Low confidence triggers HITL or a safer fallback path.
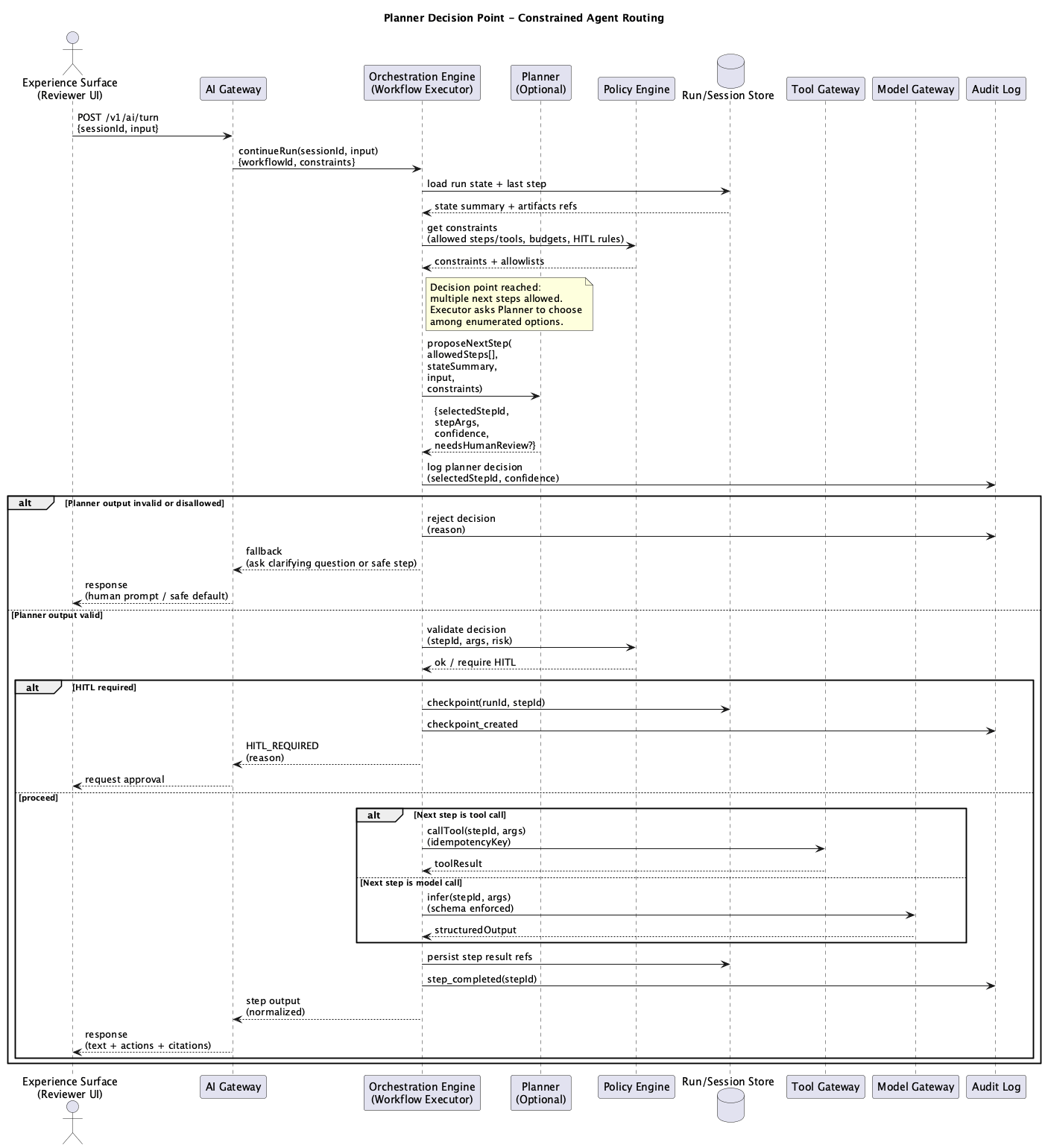 Figure 2: Planner Decision Point Sequence
Figure 2: Planner Decision Point Sequence
Planner Constraints
The Planner can only choose from approved steps in the workflow graph. It outputs structured JSON that gets schema-validated. The Executor enforces budgets and tool allowlists before execution. Planner decisions are logged to audit and replayable. Low confidence or high-risk routes trigger human-in-the-loop review.
These constraints prevent the failure modes that plague unconstrained agents. The Planner is powerful because it’s limited.
Processing a Workflow Run
 Figure 3: Orchestration Engine Sequence Diagram with branching and HITL
Figure 3: Orchestration Engine Sequence Diagram with branching and HITL
A typical workflow run proceeds through several phases.
Initialization: The Workflow Executor receives the execution request from the AI Gateway, loads the workflow definition from the Workflow Registry, initializes run state, and begins at the entry step.
Step Execution: For each step, the executor checks policy constraints, invokes the appropriate dispatcher (tool, model, or checkpoint), captures the output, updates state, and emits trace events.
Branching: When the workflow reaches a decision point, the Planner evaluates the current context and selects the next step from the allowed options. The executor validates this selection against policy before proceeding.
HITL Checkpoints: When a step triggers human review, the Checkpoint Manager pauses execution, persists state, notifies the appropriate approver, and waits for a decision. On approval, execution resumes. On rejection or timeout, the workflow follows the defined escalation path.
Completion: When the workflow reaches a terminal state, the executor finalizes the run, emits completion events, and returns the structured result to the AI Gateway.
Observability and Replay
Every step emits structured trace events. These events flow to the shared audit log and telemetry store, enabling:
Debugging: Trace a failed run step by step. See exactly what context was assembled, what the model received, what it produced, and why the workflow branched where it did.
Auditing: Answer “why did the system do X?” with evidence. Every decision is logged with causal links. Regulators and auditors can follow the chain.
Regression Testing: Replay historical runs against new workflow versions. Catch behavioral changes before they reach production.
Performance Analysis: Identify slow steps, expensive model calls, and frequent HITL triggers. Optimize based on data.
The Trace Emitter produces events like:
{
"eventType": "step.completed",
"runId": "run_abc123",
"correlationId": "corr_xyz789",
"workflowId": "case-risk-summary",
"workflowVersion": "1.2.0",
"stepId": "analyze-risk",
"stepType": "model",
"startedAt": "2026-01-09T14:23:45.123Z",
"completedAt": "2026-01-09T14:23:47.456Z",
"durationMs": 2333,
"tokensUsed": 1847,
"costUsd": 0.037,
"modelUsed": "gemini-2.5-flash",
"outputSummary": "Identified 3 risk factors: documentation gap, income verification, DTI threshold",
"nextStepId": "human-review"
}These events are the foundation for observability dashboards, alerting, and continuous improvement.
What’s Next
In the next post, we’ll explore The Tool Gateway: the governed execution boundary between AI workflows and enterprise systems. We’ll examine how tools are registered, how RBAC and policy enforcement work at the tool level, and why deterministic tool behavior is essential for reliable AI systems.
Series Roadmap
This series will explore each component of the Lattice architecture in depth:
- What Each Component Actually Is — The implementation decoder ring
- Introduction to Lattice — The Five Planes overview
- The AI Gateway — Front door and policy enforcement
- The Orchestration Engine (this post) — Workflows, not agents
- The Tool Gateway — Governed access to enterprise systems
- The Context Builder — Retrieval, redaction, and grounding
- The Model Gateway — Routing, cost control, and structured outputs
- The Control Plane — Policy, registries, and change management
- The Data Plane — Indexes, stores, and session state
- The Ingestion Plane — Document processing and embeddings
- MCP Integration — Standardized interoperability
- Preventing Hallucinations — Architectural approaches to grounding
- Lattice-Lite — A lighter approach for small orgs
- Putting It Together — End-to-end request lifecycle
This series documents architectural patterns for enterprise AI platforms. Diagrams and frameworks are provided for educational purposes.