Architecting Enterprise AI: The Lattice Platform (Part 1)

Disclaimer: This series is a personal, educational reference architecture. All diagrams, opinions, and frameworks are my own and are not affiliated with, sponsored by, or representative of my employer. I’m publishing this on my own time and without using any confidential information.
© 2026 Sean Miller. All rights reserved.
When we talk about AI, the discourse usually gravitates toward model selection, prompt engineering, and integration patterns. These are obviously important considerations, but they completely miss the mark on repeatable and safe execution at scale.
Organizations tend to think of AI as a feature or tool that can simply be plugged into a product or workflow. For example, you might use AI for data understanding and insights generation. Or you might use AI for a custom chatbot with which your partner teams can interact.
Most are building AI capabilities packaged as bespoke implementations. A product team spins up its own orchestration logic, its own retrieval pipeline, and its own safety guardrails. The result is fifty different “AI-powered features” with an equal amount of failure modes. Executives begin to balk at the lack of governance, until a TPM headcount is funded to reconcile, document, and put a strategy around all of their org’s implementations.
Lattice: A Reference Architecture for Enterprise AI Platforms
In this post, we’ll review Lattice, a reference architecture for enterprise AI platforms. Lattice is a shared capability layer with consistent observability and execution semantics. We’ll define the core problem, ungoverned AI sprawl, and introduce the Five Planes model that addresses it. From there, we’ll walk through how this layered architecture enables teams to move fast without creating chaos, and I’ll preview what the rest of the series will explore in depth.
The Problem: AI Without a Platform
Imagine what happens when a product team decides to add an AI feature today.
Figure 1: The typical pattern. Every team rebuilds the same infrastructure with different implementations.
This approach works fine for a proof of concept. It breaks down at scale for three reasons.
First, there’s no unified governance. Each implementation makes its own decisions about what the model can access, which tools it can call, and when (or whether) humans need to intervene. What’s acceptable to one team may be a compliance violation for another, and no one has visibility across the portfolio.
Second, there’s no consistent auditability. When something goes wrong, there’s no standard trail showing what context the model consumed, what tools it invoked, or why it produced a specific output. Debugging becomes archaeology, and explaining decisions to auditors becomes creative writing.
Third, there’s no shared learning. When one team improves their retrieval pipeline or discovers a better safety check, those improvements don’t propagate easily (or at all) across the org. Every team is solving the same problems in isolation, accumulating tech debt at an insane rate.
The cumulative effect is AI sprawl: a growing portfolio of fragile, inconsistent implementations that become expensive to maintain, impossible to audit, and quickly abandoned for next month’s new set of features. AI adoption then stalls because even though the technology works fine, the organizational structure to support it never materialized.
The Solution: A Shared Capability Layer
Instead of each team building their own AI stack, product teams consume AI through a governed platform that handles orchestration, tool access, retrieval, and observability on their behalf.
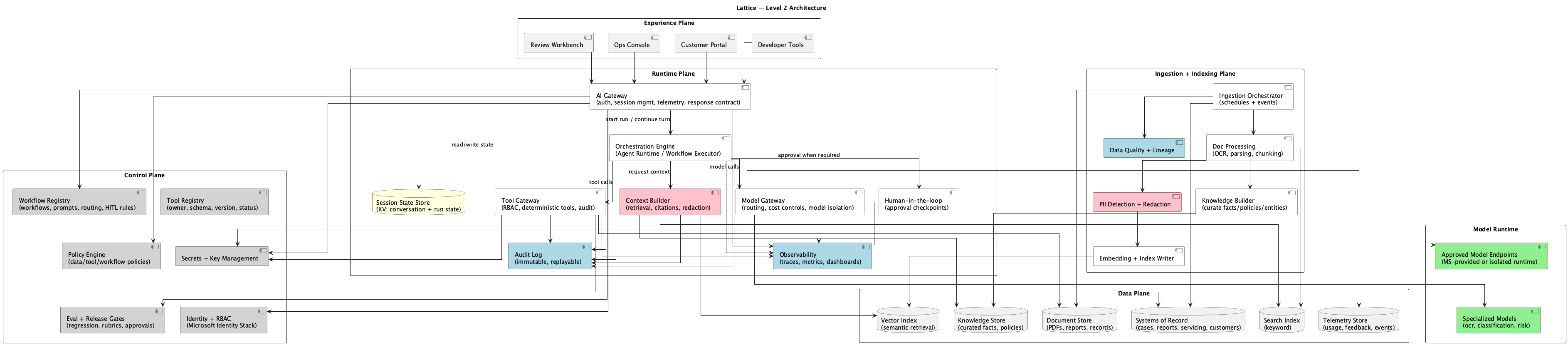
Figure 2: The Lattice model. Products consume AI through a shared runtime governed by centralized policy. Direct Link for full-size view.
Figure 3: High-level view of the Lattice Model.
The governance layer enables velocity by handling safety, auditability, and tool access in a common interface. Product teams can ship features without reinventing infrastructure in a piecemeal fashion. They focus on their domain expertise while the platform handles the cross-cutting concerns that would otherwise consume months of effort.
The Five Planes
Lattice organizes responsibilities into five distinct layers, each with a clear mandate. These layers define the organizational structure of an AI platform.
| Plane | Responsibility | Key Question It Answers |
|---|---|---|
| Experience | Where humans consume AI | ”How do users interact with AI capabilities?” |
| Runtime | Where AI executes | ”How does an intent become an output?” |
| Control | Where rules live | ”What is allowed, and who decides?” |
| Data | Where facts live | ”What information can AI access?” |
| Ingestion | Where raw becomes AI-ready | ”How does operational data become retrievable knowledge?” |
Figure 4: The Five Planes. Each layer has distinct responsibilities and communicates through defined interfaces.
Experience Plane
The Experience Plane embeds AI into the products and workflows people already use. AI surfaces feel like better versions of the products people already know, complete with clear affordances and feedback loops.
Operations dashboards with AI-powered case triage, customer portals with intelligent status explanations, and developer tools with semantic code search and runbook assistance all fall within this plane.
Runtime Plane
The Runtime Plane is the execution fabric that turns intent into output. Orchestration, tool calls, model inference, and human-in-the-loop approvals happen under strict latency and reliability constraints. It’s the factory floor of the platform.
The plane consists of five core components working in concert. The AI Gateway serves as the single entry point for all AI requests, handling authentication, routing, and response normalization. The Orchestration Engine executes workflows with proper state management, treating agentic behavior as a set of governed workflows. The Tool Gateway provides controlled access to enterprise systems. If AI is going to take action, it happens through this chokepoint. The Context Builder handles retrieval, redaction, and citation assembly, ensuring models see only what they’re supposed to see. The Model Gateway manages routing, structured outputs, and cost control across whatever model providers you’re using.
Control Plane
The Control Plane is the governing layer that decides what is allowed, what is approved, and how change happens. This is how teams move fast without creating chaos: a clear, centralized source of truth about what the platform permits.
- Policy Engine encodes rules for access, tool use, and human review triggers.
- Workflow Registry maintains versioned, approved workflow definitions that have passed through whatever governance process your organization requires.
- Tool Registry catalogs available tools with schemas, permissions, and the metadata needed to determine what any given caller is allowed to invoke.
Data Plane
The Data Plane serves as the source-of-truth and serving substrate for facts, documents, and signals. It’s organized so AI systems can retrieve what they need without leaking what they shouldn’t. This is a critical requirement when you’re dealing with sensitive enterprise data.
This includes the Vector Index for semantic search over embedded content, a Knowledge Store for curated facts and policies that should inform AI outputs, a Document Store for raw and processed documents, and Session State management for conversation history and run artifacts. The separation is important: each store has different access patterns, retention policies, and sensitivity levels.
Ingestion Plane
The Ingestion Plane is the factory that converts raw operational data into AI-ready artifacts. This layer handles document processing, embedding generation, and data quality enforcement. It’s the unglamorous work that determines whether retrieval actually works at runtime.
The components here include Document Processing (OCR, parsing, chunking of various document formats), an Embedding Pipeline for vector generation that feeds semantic search, and Data Quality enforcement for validation, deduplication, and freshness tracking. Done well, this plane is invisible. Done poorly, it’s the source of every hallucination and stale-data bug your users encounter.
Why This Structure Matters
The Five Planes model solves three critical problems that plague enterprise AI initiatives.
Separation of Concerns. Product teams own the Experience Plane. They know their users, their workflows, their domain. Platform teams own Runtime and Control. They know how to build reliable, secure infrastructure. Data teams own Ingestion and Data. They know the sources, the quality issues, the lineage requirements. Everyone knows their lane, and more importantly, everyone knows who to call when something breaks.
Consistent Governance. Every AI request flows through the same gateway, the same policy engine, the same audit trail. Compliance is baked into the platform. When regulators ask how decisions were made, you have one answer that applies across the entire portfolio, not fifty different stories to piece together.
Swappable Components. Need to change model providers? Swap the Model Gateway adapter. Need stricter retrieval for a new regulation? Update the Context Builder configuration. Need to add human review for a sensitive workflow? Update the policy rules. The architecture absorbs change without requiring every product team to update their code. This is the difference between a platform and a pile of implementations. The platform evolves as a unit.
Where This Structure Breaks Down
Lattice is a solid, foundational architecture that can power enterprise AI service offerings, but it’s not the best fit for every organization and use case. There are some limitations to consider:
- Complexity: The five planes require headcount to develop, maintain, and evolve; however, it does not require dedicated headcount and existing teams can operate on a Lattice-like implementation on a percentage basis. This includes SWEs, TPMs, Product Managers, and potentially dedicated data engineers and UX designers. If the org is small, this may not be feasible, to which a Lattice-Lite implementation may be more appropriate (covered in a future post).
- Cost: With complexity comes cost, and cost requires executive buy-in and budget allocation. Teams should perform a crisp cost-benefit analysis of the upfront and ongoing investments required to implement and maintain the platform.
- note: quantifying the cost of AI sprawl seems daunting, but we’ll cover that in a future post, too.
- Existing Infrastructure: Many reading this post are likely in a position where they have existing infrastructure offered by engineering/IT teams. This can cause friction when trying to push for new platform adoption and infra changes. Teams that are serious about AI adoption should consider cost, scope, and a gradual migration strategy for change management.
What’s Next
In the next post, “The AI Gateway: Front Door to Governed AI,” we’ll dive deep into the Runtime Plane’s entry point. We’ll explore how it authenticates requests, enforces policy, routes to workflows, and normalizes responses. The Gateway is where every AI interaction begins, and getting it right determines whether your platform feels coherent or chaotic.
Series Roadmap
This series will explore each component of the Lattice architecture in depth:
- What Each Component Actually Is — The implementation decoder ring
- Introduction to Lattice (this post) — The Five Planes overview
- The AI Gateway — Front door and policy enforcement
- The Orchestration Engine — Workflows, not agents
- The Tool Gateway — Governed access to enterprise systems
- The Context Builder — Retrieval, redaction, and grounding
- The Model Gateway — Routing, cost control, and structured outputs
- The Control Plane — Policy, registries, and change management
- The Data Plane — Indexes, stores, and session state
- The Ingestion Plane — Document processing and embeddings
- MCP Integration — Standardized interoperability
- Preventing Hallucinations — Architectural approaches to grounding
- Lattice-Lite — A lighter approach for small orgs
- Putting It Together — End-to-end request lifecycle
This series documents architectural patterns for enterprise AI platforms. Diagrams and frameworks are provided for educational purposes.